
How to Tame the AI Agent
i.e. It's All About Constraints
Large Language Models (LLMs) are getting stronger, while AI agents are getting more autonomous. In many ways this is good; the tools can solve increasingly complex problems, work on larger codebases, and produce more code. But how do we make sure that the code being generated is correct, aligns with our coding standards, and is maintainable? These are the harder problems in software engineering - problems that require experience and discipline. When we have the capability to produce code faster, we also have the capability to make a mess faster, especially if we have no or little control over the output. But how does one control the output of a coding agent in the first place? The answer is simple: by constraining it as much as possible, so that the output becomes more predictable. It's about stacking the odds in your favor – kind of like in gambling, or when crafting a well balanced character build in an RPG to have a statistically better chance against evil.
So how does one constrain their coding tool to produce the kind of code they want? All AI-assisted coding tools have some way of defining rules that their agent should follow. There's even attempts at standardizing rules across tools – like AGENTS.md, which is currently being adopted by more and more tools. You should familiarize yourself with the way agent rules work in your tool of choice. But this leads to the next question: what kinds of rules, or constraints, should you add to turn your tool from a raging bull into your trusted workhorse?
The Onion Of Constraints
We can divide these constraints into three categories, based on their role. They're called what, how, and workflow, and they all answer a different question regarding the code that is being generated. The best way to approach them is an onion model, where we start at the surface and dig deeper, layer by layer:
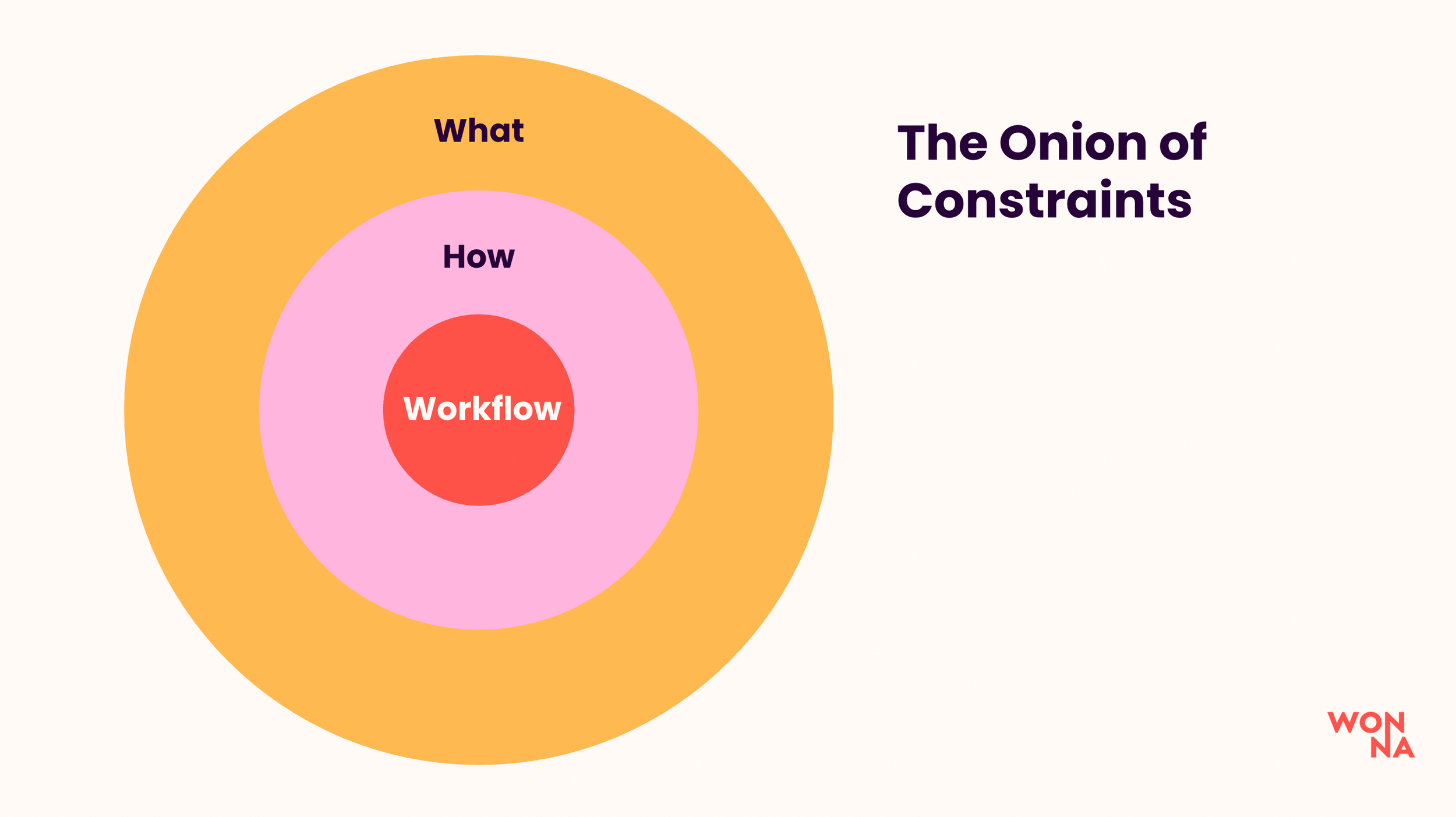
Not only is this a digestible model, it also happens to be the order in which the developer will intuitively meet the different types of constraints when mastering their tool. Let's walk through them, one layer at a time.
Type 1 : What
The what-constraint answers the question of what to implement. In practice it can be a new feature, a fix to a problem, a specification to implement, a design, etc. Sources for these can be Jira issues, bug reports, or simply just prompts to change something in the application. When the developer opens Cursor, for example, the first question they're intuitively asked is "what do I want to build?"
In theory, we can build an application only by answering the question of what to build, but as software engineers we can see how this will become a problem. The feeling of being a 10x developer – producing a lot of code and features in a short time – vanishes very fast when we hit the spot where maintainability becomes an issue; new features start introducing regression, and it seems like the AI agent starts having an increasingly harder time at producing working code.
Obviously, that's because we've forgotten to instruct the AI agent on how to build the application.
Type 2 : How
The how-constraint answers the question of how to implement code. This can begin with technology choices, go further with architectural guidelines and coding conventions, and go as far as concrete code examples on how to implement certain parts of the application. These constraints are usually provided through instructions for your specific coding agent (e.g. in .cursor/rules or AGENTS.md).
Some examples of how-constraints:
An architecture document, explaining the architecture of the application.
Coding conventions as agent instructions.
Instructions on how to lint the code correctly.
Actual code examples for building certain types of components of the application.
When we have the how in addition to the what, we significantly improve our odds of generating code that makes something happen in a way that is maintainable. While this is probably the most crucial thing to remember, we can still go further and improve the quality by defining constraints on the workflow itself.
Type 3 : Workflow
The workflow-constraints answer the question on how the agent should work when solving a problem for us. This is probably the most unintuitive category of the bunch, as surely the agent knows best on how to approach and solve a problem, right? Well, yes and no.
The agent knows how to approach a problem, but it only knows it to the extent that the underlying LLM knows, based on its training material and our context window. It doesn't automatically know anything about our codebase or our domain, so we have to get all the relevant information into our context window. Tools like Cursor or Copilot do this automatically to an extent, but we can help them out further by giving the agent instructions on how to approach different types of problems.
For example, if the developer prompts to implement a coding task, we can instruct the agent to first familiarize itself with the relevant documentation, then look for reference implementations in the code base, and only then lay out a plan to implement the task. This can be done either by giving the agent concrete steps to follow when prompting, or by writing agent instructions to do it automatically upon receiving a request from the developer.
By defining all three types of constraints – what, how, and workflow – we're able to give the agent the best possible starting point for successfully solving our problems.
Explicit vs Implicit Constraints
While there are a bunch of constraints that we need to define explicitly, there is even more constraints applied all the time. These are the implicit constraints that we don’t see. The tools and services we use – whether it's Cursor, Copilot, Claude Code, or something else – apply a lot of constraints on their own to enhance both the user experience and the quality of the agent's work. LLM's are only a part of this equation, as the final prompt that will reach the LLM will include both the explicit constraints written by us, and the implicit constraints written by the developers of the service.
It's important to remember that they're there, because that means that there's also a lot of prompt engineering that the developer doesn't need to worry about, at least when compared to using a raw LLM through an API.
Conclusion
LLMs need constraints in the form of agent instructions. When applying constraints, it helps to divide them into three categories:
What: Answers the question of what to implement.
How: Answers the question of how to implement.
Workflow: Answers the question of how the agent should work when solving a problem for us.
It's also good to remember that regardless of the tool of choice, it complements these explicit constraints with it's own implicit constraints.With this in mind, you will have the best chance of taming your coding agent.

Author
Tommi Sinivuo
As Wonna’s AI Lead, Tommi is the driving force behind our Exploring the Future of Coding journey. With nearly 15 years in software—mostly on the backend and DevOps side—they combine hands-on expertise with a passion for sustainability. Tommi has been exploring and applying AI-assisted development tools since their earliest public releases, gaining deep, practical insight into how these technologies reshape software development work.